

















# 1. 前言
非常感谢虎哥给我带来这篇 Redis 基础原理知识的讲解 , 让我更深刻地理解了 Redis 的设计思想和数据结构 . 从最基本概念到高级特性 , 虎哥想逐层讲解 , 让我们受益匪浅
# 2. 数据结构
# 2.1 SDS
Redis 构建了一种新的字符串结构 , 称为简单动态字符串(SDS)
C 语言中的字符串 , 是通过数组形式拼接字符 , 因此没有直接使用语言中的字符串 , 并且当中也存在很多问题 :
- 获取字符串长度的需要通过运算
- 非二进制安全
- 不可修改
优点 :
- 操作快 , 简单 , 灵活 (有标识记录长度等相关信息 , 用于检索数组操作)
- 动态扩容 (含有扩容相关机制)
- 二进制形式 , 相对安全
缺点 :
- 占用内存 (结构体包含的元数据过多)
- 功能有限 (仅限于读写操作 , 没有其他相关拓展功能)
SDS 结构体源码 :
源码 点击展开
/* 控制SDS的头类型大小 */#define SDS_TYPE_5 0#define SDS_TYPE_8 1#define SDS_TYPE_16 2#define SDS_TYPE_32 3#define SDS_TYPE_64 4
/* sdshdr8 结构体名称 . 有很多个相同结构 如上面... */struct _attribute_ ((_packed_)) sdshdr8 { /* uint8_t : 无符号8个bit位 */ /* buf已保存的字符串字节数 , 不包含结束标识 */ uint8_t len; /* buf申请的总字节数 , 不包含结束标识 */ uint8_t alloc; /* 不同SDS的头类型 , 用来控制SDS的头大小 */ unsigned char flags; char buf[];}flags 意图
uint8_t 定义的是 无符号 8 个 bit 位 , 8bit 位长度就仅限于 0 - 255 的大小 , 那么通过 len 和 alloc 控制的长度不可能仅限于 0 - 255 , 因此 通过 flags 控制字节大小 , 尽可能将 8bit 压缩在 0 - 255 数值范围
PS : 1 字节 = 8 位
假如我 Redis 执行该命令 set name Sans . 那么 Redis 将在底层创建两个 SDS , 分别对 {“name”, “Sans”} 结构分析 :
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | lan | 4 | 1 |
| Header | alloc | 4 | 1 |
| Header | flags | 1 | 1 |
| Data | buf[] | [‘n’,‘a’,‘m’,‘e’] | 4(1*4) |
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | lan | 4 | 1 |
| Header | alloc | 4 | 1 |
| Header | flags | 1 | 1 |
| Data | buf[] | [‘S’,‘a’,‘n’,‘s’] | 4(1*4) |
假如 往”Sans” SDS 追加一段字符 “,Any” , 那么会执行内存拓展申请 : (申请有两种可能)
- 如果新字符串小于 1M , 则 增加后的长度两倍 + 1
- 如果新字符串大于 1M , 则 增加后的长度两倍 + 1M +1 (内存预分配)
那么 “Sans” 这变为 “Sans,Any” , SDS 结构分析
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | lan | 8 | 1 |
| Header | alloc | 12 | 1 |
| Header | flags | 1 | 1 |
| Data | buf[] | [‘S’, ‘a’, ‘n’, ‘s’, ’,’, ‘A’, ‘n’, ‘y’] | 8(1*8) |
提示
C 语言字符串结尾必须有 \0 作为结束 , 因此 计算后的长度需要+1 , 就是为结束标示而腾出的位置
# 2.2 IntSet
IntSet 是 Redis 中 set 集合的一种实现方式 , 基于 整数数组 来实现 , 并且具备 长度可变/有序 等特征
为了方便查找 , Redis 会将 intset 中所有的整数按照升序依次保存在 contents 数组中
优点 :
- IntSet 确保元素 唯一 , 有序
- 类型升级机制 , 节省内存
- 快速查找 (内部采用二分查找算法)
- 内存连续 (存储是连续形式 , 充分利用资源)
缺点 :
- 只能用于整型
- 内存浪费 (当数组中有一个元素大数字 , 且其他都是小元素)
- 不能范围查找 (指定范围查元素)
IntSet 结构体源码 :
源码 点击展开
/* 存放 encoding , 表示不同整型大小 *//* 2字节 整数 , 类以java的short */#define INTSET_ENC16 (sizeof(nt16t_t))/* 4字节 整数 , 类以java的int */#define INTSET_ENC32 (sizeof(nt32t_t))/* 8字节 整数 , 类以java的long */#define INTSET_ENC64 (sizeof(int64_t))
typedef struct intset { /* 编码方式 , 支特存放16位、32位、64位整数 */ uint32_t encoding; /* 元素个数 */ uint32_t length; /* 整数数组 , 保存集合数据 */ int8_t contents[];}intset;假如 使用 intset 存了 {20, 5, 10} 3 个元素 , 采取编码 INTSET_ENC16(2 字节) , IntSet 结构分析 :
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | encoding | INTSET_ENC16 | 4 |
| Header | length | 3 | 4 |
| Data | contents[] | [5,10,20] | 6(2*3) |
提示
上面定义了采用的类型因此存储的字节是不一样的! 采用了 INTSET_ENC16 类型 2 字节
假如 数组添加了一个 5000 , 大于 INTSET_ENC16(2 字节) 的范围 , IntSet 会自动升级编码方式找到合适大小 , 升级流程 :
- 升级编码 INTSET_ENC_INT32(4 字节) , 并按照新的编码方式及元素个数扩容数组
- 倒序依次将数组中的元素拷贝到扩容后的正确位置
- 将 5000 元素 添加放入数组末尾
- IntSet 的 encoding 属性改为 INTSET_ENC_INT32 ; length 属性改为 4
提示
步骤 2 倒序扩容是为了防止前面的数在扩容时覆盖其他数据 . 一号元素占用 2 字节改为 4 字节 , 会占用到第二元素位置的 2 字节 .
为了防止这一现象 , 采用倒序扩容 , 从最后元素开始扩容 !
结构分析 :
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | encoding | INTSET_ENC32 | 4 |
| Header | length | 4 | 4 |
| Data | contents[] | [5,10,20,5000] | 16(4*4) |
# 2.3 Dict
Redis 中的键值对映射关系底层是通过 Dict 实现的 , 它涉及到 键值对 , 哈希表 , 有序集合等相关应用
Dict 的底层是由 数组和链表 组合 , 数组中每个元素都是一个指向链表的指针 , 每个链表节点包含一个键值对
优点 :
- 读写快 (O(1)时间复杂度)
- 动态 扩容/收缩 (根据实际情况变化内存)
- 支持高并发
缺点 :
- 占用内存多 (动态数组 , 相对少量数据可能比较浪费空间)
- 哈希可能冲突 (较为极端的例子)
- 不支持持久化 (dict 基于内存存储)
Dict 结构体源码 :
源码 点击展开
typedef struct dict { // dict类型 , 内置不同的hash函数 dictType *type; // 私有数据 , 在做特殊hash运算时用 void *privdata; // 一个Dict包含两个哈希表 , 一个是当前数据 , 另一个 rehash时使用(一般为空) dictht ht[2]; // rehash的进度 , -1:未进行; rehashidx > -1:运行 long rehashidx; // rehash是否暂停 , 1:暂停;0:继续 int16_t pauserehash;}dict;
typedef struct dictht { // entry数组 // 数组中保存的是指向entry的指针 dictEntry **table; // 哈希表大小 unsigned long size; // 哈希表大小的掩码 , 总等于size-1 unsigned long sizemask; // entry个数 unsigned long used;}dictht;
// 哈希节点 dictEntrytypedef struct dictEntry { // 键 key void *key; // 值 val union { void *val; uint64_t u64; int64_t s64; double d; }; // 下一个Entry的指针 struct dictEntry *next;}dictEntry;结构图 :
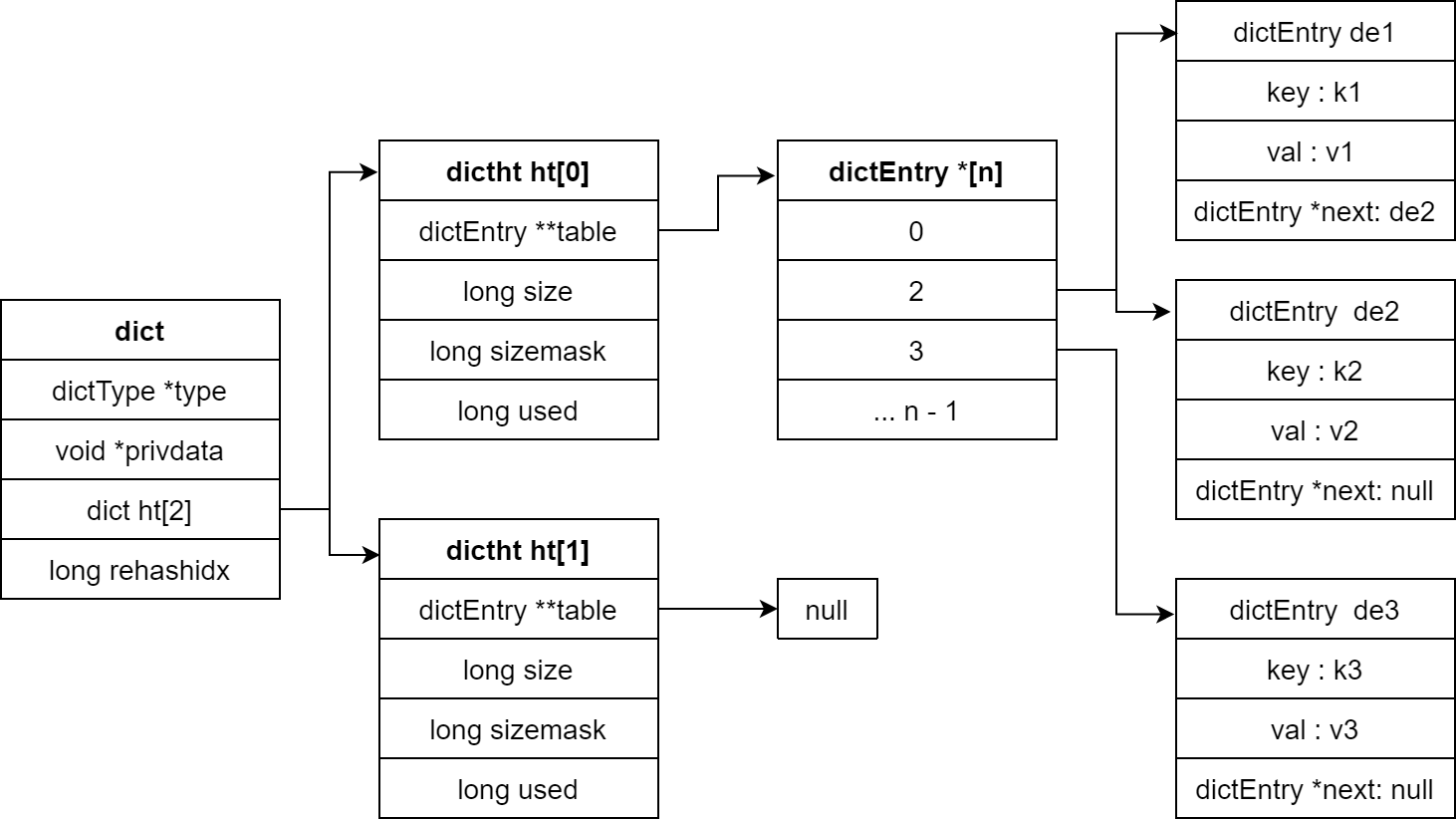
# 2.3.1 扩容机制
Dict 中的 table 是数组与单向链表 的结构 , 当集合的元素较多时 , 必然会导致哈希冲突 , 和链表过长问题 , 甚至会影响效率 因此 Dict 内置了 自动扩容机制 , 当每次新增键值对的时 , 会检测 负载因子(LoadFactor) , 判断以下两种条件会触发扩容 :
- LoadFactor >= 1 , 并且 Redis 没有进行持久化
- LoadFactor > 5
计算公式 : 负载因子(LoadFactor) = used(当前元素总数)/size(空间总数)
扩容运作过程 :
- 创建 新 Hash , 新 Hash 大小为 原 Hash 元素总数+1 的 2^n (简单理解为 2 倍)
- 将 原 Hash 所有元素逐个遍历 , 插入 新 Hash (重新分配 哈希桶 , 防止 hash 冲突)
- 插入完后 Redis 会将 原 Hash 释放
提示
dict.ht[0] = 原 Hash
dict.ht[1] = 新 Hash
扩容中的特殊情况
扩容中插入元素 :
在扩容中若有 新元素 插入 , Redis 会将 新元素 先插入 原 Hash 中 , 再将 原 Hash 所有元素逐个遍历插入至 新 Hash (利用 key 唯一性 , 保证了 新元素 不会缺漏)
扩容中多线程操作 dict :
在扩容中 , 如果有多个线程同时对 dict 进行操作 , Redis 会采取读写锁机制保证 dict 的线程安全
扩容机制源码 :
源码 点击展开
static int _dictExpandIfNeeded(dict *d){ // 如果正在rehash , 则返回ok if (dictIsRehashing(d)) return DICT_OK; // 如果哈希表为空 , 则初始化哈希表为默认大小 : 4 if (d->ht[o].size = 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); // 当负载因子(used/size)达到1以上 , 并且当前没有进行ogrewrite(持久化过程) // d->ht[0].used >= d->ht[0].size => (used/size)达到1以上 // dict_can_resize (Redis是否闲置状态 , 非持久化状态) // d->ht[0].used/d->ht[0].size > dict_force_resize_ratio => 负载因子超过5 , 则进行dictExpand(扩容) if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)){ // 扩容大小为used + 1 , 底层会对扩容大小做判断 , 实际上找的是第一个大于等于 used + 1 的 2^n return dictExpand(d, d->ht[0].used+1); } return DICT_OK;}# 2.3.2 收缩机制
Dict 还有收缩机制 , 正是和扩容机制相反 . 每当删除元素的时候 , 会检测 负载因子(LoadFactor)
触发条件 : LoadFactor < 0.1
收缩源码 :
源码 点击展开
//t_hash.c hashTypeDeleted()// 删除元素if (dictDelete((dict*)o->ptr, field) == C_OK) { deleted 1; // 删除成功后 , 检查是否需要重置Dict大小 , 如果需要则调用dictResize重置 if (htNeedsResize(o->ptr)) dictResize(o->ptr);}...
// server.c文件// 检查是否需要收缩int htNeedsResize(dict *dict) { long long size,used; // 哈希表大小 size = dictslots(dict); // entry数量 used = dictsize(dict); // size > 4 (哈希表初识大小) && 负载因子低于0.1 // DICT_HT_INITIAL_SIZE: 4 ; HASHTABLE_MIN_FILL: 10 // (used*100/size < HASHTABLE_MIN_FILL) => user/size < 0.1 return (size > DICT_HT_INITIAL_SIZE && (used*100/size < HASHTABLE_MIN_FILL));}
int dictResize(dict *d) { unsigned long minimal; // 如果正在做 bgsave或ogrewriteof或rehash , 则返回错误 if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; // 获取used , 也就是entry个数 minimal = d->ht[0].used; // 如果used小于4 , 则重置为4 if (minimal < DICT_HT_INITIAL_SIZE) minimal = DICT_HT_INITIAL_SIZE; // 重置大小为ninimal , 其实是第一个大于等于minimal的2^n return dictExpand(d, minimal);}# 2.3.3 rehash
rehash 是 dict 的一种重建哈希表的机制(扩容/收缩 新 Hash) . 当 dict 的 size 发生变化 , 都会检测 扩容/收缩 条件 , 为此要 将 原 Hash 中的所有键值对重新插入到 新 Hash 中 , 这个过程叫做 rehash
rehash 运作原理 :
- 计算 新 Hash 的大小 , 取决于当前 扩容/收缩
- 扩容 : 新 size >= 原 Hash 元素总数+1 的 2^n
- 收缩 : 新 size >= 原 Hash 元素总数 的 2^n (不得小于 4)
- 新 Hash 申请内存空间 , 创建 dictht , 并赋值给 dict.ht[1]
- 设置 dict.rehashidx = 0 , 标示 开始 rehash (可以理解成数组的索引)
- 检查 dict.rehashidx > -1 , 如果是则将 dict.ht[0].table[rehashidx]的 键值对 插入 dict.ht[1] , 并且 rehash++ , 直到 dict.ht[0] 所有数据都插入完 (插入时 会重新分配 hash 值)
- 插入完后 , 给 dict.ht[1]初始化为空哈希表 , 释放原来的 dict.ht[0]的内存
- 将 dict.rehashidx = -1 , 标示 结束 rehash
rehash 中的其他情况
rehash 中插入元素 :
直接写入 dict.ht[1]
rehash 中多线程操作 dict :
dict.ht[0] 和 dict.ht[1] 并行执行 互不干扰 , 保证 dict.ht[0] 只减不增 , 最终 rehash 结束 , 原 Hash 为空
提示
dict.ht[0] = 原 Hash
dict.ht[1] = 新 Hash
rehash 源码 :
源码 点击展开
// dict.c 文件// 伸缩控制 dictExpand (参数3可以无视)int _dictExpand(dict *d, unsigned long size, int* malloc_failed) { if (malloc_failed) *malloc_failed = 0;
/* 检查 状态/申请合理 , 如果 entry数量超过要申请的size大小 或 正在rehash , 则报错 */ if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR;
/* 新声明 hash table */ dictht n; // 实际大小(下面有函数说明) , size <= 2^n(2^n为刚好大于或等于size) unsigned long realsize = _dictNextPower(size);
/* 检查内存溢出 , 超出 LONG_MAX , 报错 */ if (realsize < size || realsize * sizeof(dictEntry*) < realsize) return DICT_ERR;
/* 检查变化 , 新size如果和原size 一致 , 报错 */ if (realsize == d->ht[0].size) return DICT_ERR;
/* 分配新的哈希表并将所有指针初始化为 NULL */ // 重置大小 n.size = realsize; // 重置掩码 n.sizemask = realsize-1; if (malloc_failed) { n.table = ztrycalloc(realsize*sizeof(dictEntry*)); *malloc_failed = n.table == NULL; if (*malloc_failed) return DICT_ERR; } else{ // 分配内存: size * entrySize n.table = zcalloc(realsize*sizeof(dictEntry*)); } n.used = 0;
/* 如果是第一次 , 则直接把n复制给ht[0] */ if (d->ht[0].table == NULL) { d->ht[0] = n; return DICT_OK; }
/* 准备第二个哈希表以进行增量重新哈希 */ d->ht[1] = n; d->rehashidx = 0; return DICT_OK;}
// 2^n计算static unsigned long _dictNextPower(unsigned long size) { // DICT_HT_INITIAL_SIZE: 4 unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX + 1LU; while(1) { if (i >= size) return i; i *= 2; }}# 2.4 ZipList
ZipList 是个特殊的 双向链表 , 它把小数据的内存压缩到极致 , 元素是由连续不确定形式的内存块组成(每个元素内存不定) .
在 Redis 中常用于 List 和 Zset 的基础数据结构
优点 :
- 紧凑式存储 (省内存)
- 读写快
缺点 :
ZipList 结构体源码 :
源码 点击展开
typedef struct ziplist {
// 记录整个ZipList的字节数(4字节) unsigned uint32_t zlbytes; // 指向ZipList的最后一个节点的偏移量(从开头指向最后元素的开始)(4字节) unsigned uint32_t zltail; // 记录ZipList中元素总量(2字节) unsigned uint16_t zllen;
// 以下是实际的数据存储空间 , 这个空间是紧凑的字节数组 // 每个节点包含一个前置节点长度的字段prevlen和一个实际存储数据的entry字段 // entry字段可以是字符串、整数或者浮点数 , 长度根据实际数据类型使用不同的字节数 unsigned entry data[]; // 结束符(1字节) unsigned uint8_t zlend;
} ziplist;ZipListEntry 结构体
ZipListEntry 是 data[]中的元素 , Entry 的并不像普通链表那样记录前后节点的指针 , 采用以下结构记录不同类型的数据
| previous_entry_length | encoding | content |
|---|
-
previous_entry_length: 前置 Entry 的长度所占的字节数(1/5 字节)
- 如果 前置 Entry 长度 < 254 , 采用 1 字节
- 如果 前置 Entry 长度 >= 254 , 采用 5 字节 , 第一个字节为 0xfe(2^8-1) , 后面为真实长度
-
encoding : 编码属性 , 记录 content 数据类型 , (1/2/5 字节)
-
content : 负责保存节点的数据 , 可以是字符串或整数
# 2.4.1 encoding 编码
ZipListEntry 中的 encoding 编码分为 整数和字符串两种 :
- 字符串 头标识
00(1 字节)/01(2 字节)/10(5 字节) - 整型 头标识
11(1 字节)
字符串
| 编码 | 编码长度 | 字符串 | | ---- | --------- | --------- | --------- | ----------- | -------------- | --- | ------- | ------------------- | | | 00pp pppp | | 1 bytes | <= 63 bytes | | | 01pp pppp | qqqq qqqq | | 2 bytes | <= 16383 bytes | | | 1000 0000 | qqqq qqqq | rrrr rrrr | ssss ssss | tttt tttt | | 5 bytes | <= 4294967295 bytes |
提示
含有字母的代表存真实内存空间
假如 分别存储字符串 {“ab”, “bc”} , 那么对 ZipList 结构体 内存分析 :
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | zlbytes | 19 | 4 |
| Header | zltail | 14 | 4 |
| Header | zllen | 2 | 2 |
| Data | entry[0] | “ab” | 4 |
| Data | entry[1] | “bc” | 4 |
| Tail | zlend | 0xff | 1 |
ZipListEntry 结构体 分析 : (Entry 的 “ab”和”bc”)
| 标识 | 属性 | 值 | 字节 | | ------ | --------------------- | ---------------- | ----------- | --- | | Header | previous_entry_length | 0000 0000 (0x00) | 1 | | Header | encoding | 0000 0010 (0x02) | 1 | | Data | content | 0x61 | 0x62 (“ab”) | 2 |
| 标识 | 属性 | 值 | 字节 | | ------ | --------------------- | ---------------- | ----------- | --- | | Header | previous_entry_length | 0000 0100 (0x04) | 1 | | Header | encoding | 0000 0010 (0x02) | 1 | | Data | content | 0x62 | 0x63 (“bc”) | 2 |
整数
encoding 编码 以 11 代表 content 为整型 , 固定占用 1 字节
| 编码 | 编码长度 | 整型类型 |
|---|---|---|
| 11000000 | 1 bytes | int16_t(2 bytes) |
| 11010000 | 1 bytes | int32_t(4 bytes) |
| 11100000 | 1 bytes | int64_t(8 bytes) |
| 11110000 | 1 bytes | 24 位有符整数(3 bytes) |
| 11111110 | 1 bytes | 8 位有符整数(1 bytes) |
| 1111xxxx | 1 bytes(含数据) | 直接在 xxxx 位置保存数值 , 范围从 0001~1101 , 减 1 后结果为实际值 |
假如 分别存储 {65536 , 3} , 那么对 ZipList 结构体 内存分析 :
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | zlbytes | 19 | 4 |
| Header | zltail | 16 | 4 |
| Header | zllen | 2 | 2 |
| Data | entry[1] | 65536 | 6 |
| Data | entry[0] | 3 | 2 |
| Tail | zlend | 0xff | 1 |
ZipListEntry 结构体 分析 : (Entry 的 3 和 65536)
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | previous_entry_length | 0000 0000 (0x00) | 1 |
| Header | encoding | 1101 0000 (0xd0) | 1 |
| Data | content | 65536 | 4 |
| 标识 | 属性 | 值 | 字节 |
|---|---|---|---|
| Header | previous_entry_length | 0000 0110 (0x06) | 1 |
| Header-Data | encoding | 1111 0010 (0xf4) | 1 |
| Data | content | 0010(0x04) => 4 - 1 = 3 | - |
特殊编码标识
1111 xxxx , 高位 1111 代表编码标识 , 低位 xxxx 代表存储的数据 , 低位仅限范围 0001 - 1101
- 1111 0000(0xf0) 代表 24 位有符整数
- 1111 1111(0xff) 代表 结束符
- 1111 1110 代表 8 位有符整数
低位的编码 不能容许相同形式的出现 : 因此 低位 最小值为 0001 ; 最大值为 1101
那么 他的范围仅限于 1 - 14 , 为了临近实际值 , 因此实际范围为 0 - 13
假如 存储 5 , 那么存储范围则为 1111 00110 => 结果值 6 => 实际值 5
# 2.4.2 连锁更新问题
ZipListEntry 的 previous_entry_length 用来记录上一 Entry 节点的直接大小 , 记录的结果只有两种情况分别是 1 / 5 字节 两种
案例 :
假如 ZipList 链表中有 N 个连续且长度为 249 - 254 字节之间的 Entry , 这 N 个 Entry 的 previous_entry_length 也好只用 1 字节存储 , 如果在 ZipListEntry 头结点添加一个 254 字节的 Entry (触发下一节点 previous_entry_length 采用 5 字节) , 那么后面的 Entry 的 previous_entry_length 也随之变化变为 5 , 卡点 254(249+5) , 从而身亲大量不必要的内存 , 像这种情况连续性多次空间拓展 称为 连锁更新 .
笔记
以上是非常极端的情况 , 发生概率极低 , 作者目前也没对其解决
# 2.5 QickList
QickList 是 双向链表和压缩列表 的混合结构 . QickList 的每个节点都包含一个 ZIpList , 用于存储多个连续列表元素 , 过个节点之间是相互链接的 . 其目的是节省内存的同时 , 还保持良好的性能 . 在 Redis 中用于 List 数据结构
优点 :
- 节省内存 (QickList 管理 ziplist 连续元素)
- 效率高 (头尾 增删快 , 满足列表特性)
缺点 :
- 访问中间元素新能差 (需要遍历)
QickList 结构体源码 :
源码 点击展开
typedef struct quicklist { // 头节点指针 quicklistNode *head; // 尾节点指针 quicklistNode *tail; // 所有ziplist的entry数量 unsigned long count; // ziplists总数量 unsigned long len; // ziplist的entry上限 , 默认-2 int fill : QL_FILL_BITS; // 首尾不压缩的节点数量 unsigned int compress : QL_COMP_BITS; // 内存重分配是的书签数量以及数组(一般怎么用) unsigned int bookmark_count: QL_BM_BITS; quicklistBookmark bookmarks[];} quicklist;
// ziplist节点typedef struct quicklistNode { // 前一个节点指针 struct quicklistNode *prev; // 下一个节点指针 struct quicklistNode *next; // 当前ziplist节点 指针 unsigned char *zl; // 当前ziplist节点 字节大小 unsigned int sz; // 当前ziplist节点 entry个数 unsigned int count : 16; // 编码方式: 1.ziplist; 2.lzf压缩 unsigned int encoding : 2; // 数据容器类型: 1.其他; 2.ziplist unsigned int container : 2; // 当前ziplist节点 是否被解压缩: 1.被解压了, 需要重新压缩 unsigned int recompress : 1; // 测试用 unsigned int attempted_compress : 1; // 预留字段 unsigned int extra : 10;} quicklistNode;结构图 :

# 2.5.1 Redis 配置项
涉及到 QickList 配置项有 :
- list-max-ziplist-size 控制大小
- list-compress-depth 节点压缩
list-max-ziplist-size
控制 QuickList 中的 每个 ZipList 大小 , 通过 数值控制 , 如下 :
- 正数 : 指定 ziplist 允许最大 entry 个数
- 负数 : 指定 ziplist 最大内存大小
负数内存大小指定说明 :
| 配置项值 | 说明 |
|---|---|
| -1 | 每个 ZipList 内存大小 <= 4kb |
| -2 | 每个 ZipList 内存大小 <= 8kb (默认值) |
| -3 | 每个 ZipList 内存大小 <= 16kb |
| -4 | 每个 ZipList 内存大小 <= 32kb |
| -5 | 每个 ZipList 内存大小 <= 64kb |
提示
1 kb = 1024 bytes(字节)
list-compress-depth
控制 QuickList 中的 ZipList 节点做压缩 , 通过 数值控制 , 如下 :
- 0 : 特殊值 , 不压缩(默认)
- 1 : QuickList 的首尾各一个节点不压缩 , 中间节点压缩
- N : QuickList 的首尾各 N 个节点不压缩 , 中间节点压缩
# 2.6 SkipList
SkipList(跳表)是有序的双向链表的数据结构 , 节点可能含有多节点指针 , 不同跨度 , 其目的是为了 插入/删除/查询 速度都达到 O(log n) , 在 Redis 中用于 ZSet 数据类型
优点 :
- 查询效率堪比二分查找
- 实现简单 , 容易维护
缺点 :
- 消耗内存空间 (空间换时间)
SkipList 结构体源码 :
源码 点击展开
typedef struct zskiplist { // 头尾节点指针 struct zskiplistNode *header, *tail; // 节点数量 unsigned long length; // 最大的索引层级(默认1 ;最大20) int level;}zskiplist;
typedef struct zskiplistNode { // 节点存储的值 sds ele; // 节点分数 , 排序、查找用 double score; // 前一个节点指针 struct zskiplistNode *backward; // 多级 索引数组 struct zskiplistLevel { // 下一个节点指针 struct zskiplistNode *forward; // 索引跨度 unsigned long span; }level[0]:}zskiplistNode;结构图 :
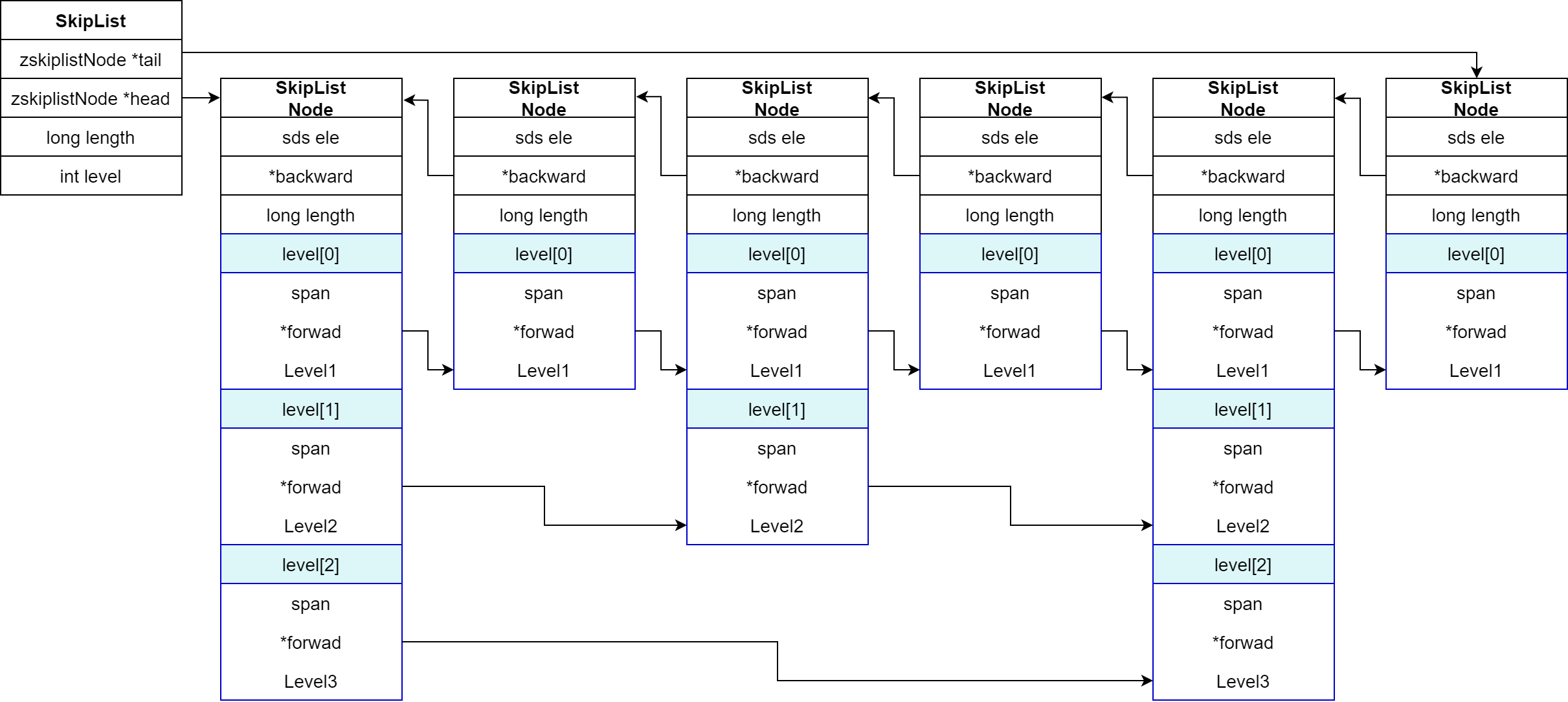
# 2.7 RedisObject
Redis 中的任意数据类型的键和值都会被封装为一个 RedisObject
SkipList 结构体源码 :
源码 点击展开
typedef struct redisobject { // 对象类型(4bit)(string;hsah;list;set;zset) unsigned type:4; // 底层编码方式(4bit) unsigned encoding:4; // 最后一次访问的时间戳(24bit)(判断闲置过久的key) // LRU: 以秒单位记录最近一次访问时间 , 长度(24bit) // LFU: // - 高16位以分钟为单位记录最近一次访问时间 // - 低8位记录逻辑访问次数 unsigned lru:LRU_BITS; // 对象引用计数器(4bytes)(0:对象无人引用; 每次引用+1) int refcount; // 真实对象数据指针(8bytes) void *ptr;}robj;Redis 存储数据类型的encoding 编码
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw 编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long 类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | hash 表(字典 dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr 的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream 流 |
Redis 每种数据类型的使用的编码方式
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int ; embstr ; raw |
| OBJ_LIST | LinkedList 和 ZipList(3.2 以前) ; QuickList(3.2 以后) |
| OBJ_SET | intset ; HT |
| OBJ_ZSET | ZipList ; HT ; SkipList |
| OBJ_HASH | ZipList ; HT |
# 2.8 String
Redis 最常见类型 String , 其编码有 :
-
RAW 编码 , 存储上限 512mb (基于 SDS 实现)
-
EMBSTR 编码
采用条件 : 当 SDS 总长度小于 44 字节
-
INT 编码
采用条件 : 字符串中内容是整数值 , 且大小为 LONG_MAX 范围内
笔记
EMBSTR 编码
RAW 编码 在 RedisObject 中是需要指针 *ptr 指向外部的 SDS 内存地址来引用 , 而 EMBSTR 编码 在 RedisObject 中是一对连续空间 , 只需申请一次内存分配函数即可实现 . 无需指针指向外部地址 , 能节省更多空间 , 无需寻址 , 效率更高
INT 编码
INT 编码 直接在 RedisObject 中的 *ptr 位置抽出刚好的 8 字节空间存储
三种类型的结构图 :
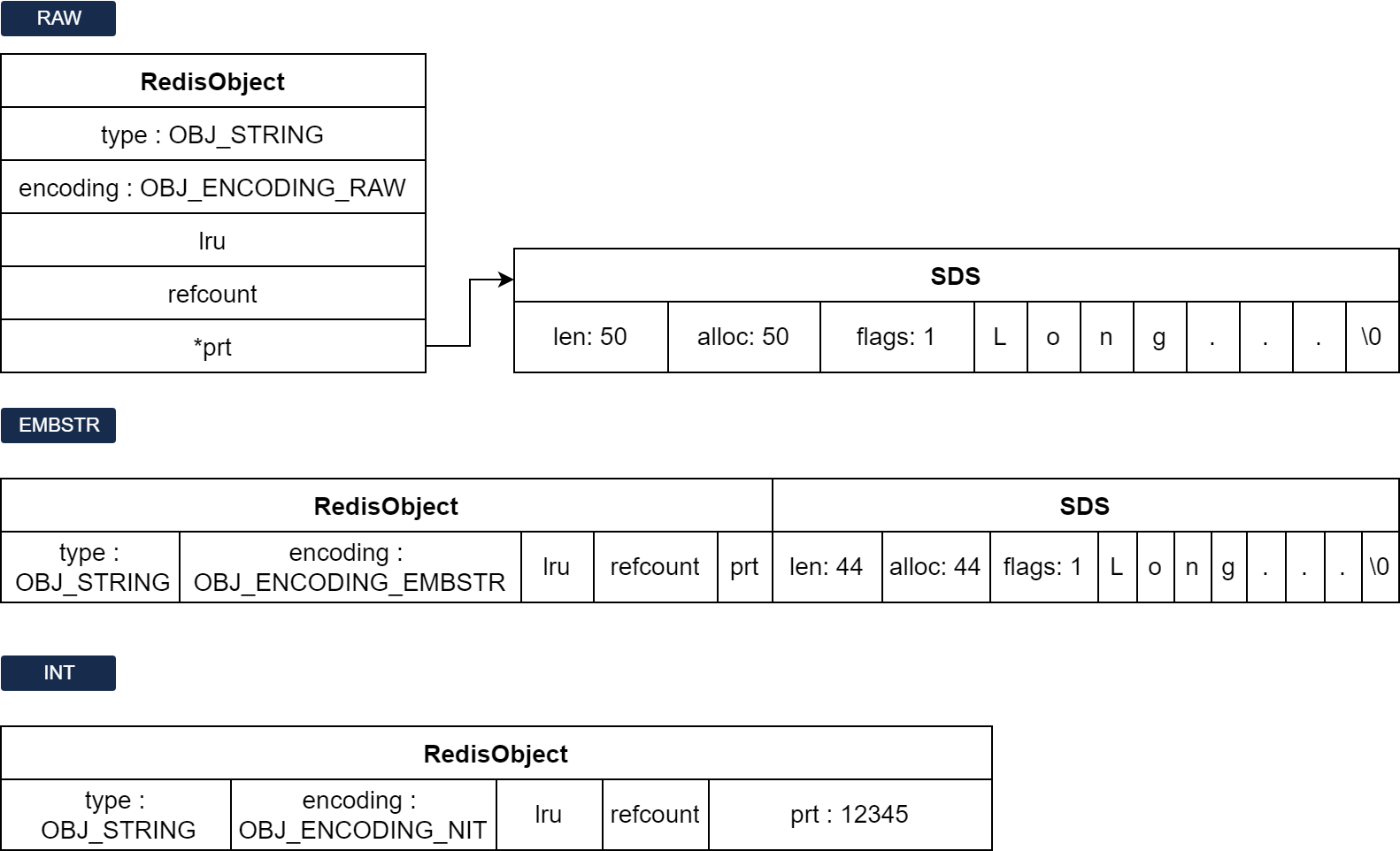
# 2.9 List
Redis 的 List 类型 可从首尾进行操作元素 , 底层通过 [QickList](#2.5 QickList)实现(3.2 版本后)
Push 源码
源码 点击展开
/** push源码 client: 客户端信息,当中包含有命令 where: 0:头新增; 1:尾新增 xx: 当前push的key存在**/void pushGenericCommand(client *c, int where, int xx) { int j; // 判断元素大小 , 不能超过LIST_MAX_ITEM_SIZE // LPUSH key v1 v2 ... (跳过前面两个 , 从2开始 for (j = 2; j < c->argc; j++) { // 遍历参数 argv[] if (sdslen(c->argv[j]->ptr) > LIST_MAX_ITEM_SIZE) { addReplyError(c, "Element too large"); return; } }
// 尝试找到KEY对应的list . 选择指定库db , argv[1]: key robj *lobj = lookupKeyWrite(c->db, c->argv[1]); // 检查类型是否正确 if (checkType(c,lobj,OBJ_LIST)) return; // 判断空 if (!lobj) { if (xx) { addReply(c, shared.czero); return; } // 为空情况 , 创建新的QuickList lobj = createQuicklistObject(); quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,server.list_compress_depth); dbAdd(c->db,c->argv[1],lobj); }
for (j = 2; j < c->argc; j++) { listTypePush(lobj,c->argv[j],where); server.dirty++; }
addReplyLongLong(c, listTypeLength(lobj));
char *event = (where == LIST_HEAD) ? "lpush" : "rpush"; signalModifiedKey(c,c->db,c->argv[1]); notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);}结构图 :
# 2.10 Set
特点 :
- 元素无序
- 元素唯一
- 求 交集/并集/差集
Set 编码选型 :
- HT 编码 , 采取 Dict 实现 , 也是默认应用
- IntSet 编码 采用条件 : 但所有元素都是整数 , 且这些数值不超过 set-max-intset-entries 最大值
IntSet 编码转化 HT 编码情况
在采用 IntSet 编码的时 , 每当 插入/更改 元素 , 都会检测该元素的类型是否满足 , 如果不满足则转换为 HT 编码
条件 :
- 元素值为整数
- 数值 < set-max-intset-entries
# 2.11 ZSet
ZSet 集合 , 每个元素都要指定一个 score 值和 member 值
特点 :
- score 值排序
- member 唯一
- member 查询
ZSet 需要具备以上特性才能满足 , 因此会有以下数据结构组合方式 :
- SkipList 和 Dict , 功能互补 , 效率高 , 耗内存 (SkipList 无法满足 member 查询)
- ZipList , 节省内存 . 以下采用条件 :
- 元素数量 < zset_max_ziplist_entries , 默认 128(可配置)
- 每个元素 < zset_max_ziplist_value 字节 , 默认值 64(可配置)
ZipList 怎么作为 ZSet 来应用
ZipList 是对连续内存 , 因此 score 和 element 紧挨在 Entry , element 在前 , score 在后 . score 越小越接近队首 , 反之越靠尾 (升序)
提示
当采用 ZipList 时 , 每次添加元素都会检测元素是否满足条件 , 从而判断是否转化 SkipList 和 Dict 结构
ZSet 实现源码 :
源码 点击展开
SkipList 和 Dict
// zset结构typedef struct zset { // Dict指针 dict *dict; // SkipList指针 zskiplist *zsl;}zset;
// 创建robj *createZsetobject(void) { zset *zm = zmalloc(sizeof(*zs)); robj *o; // 创建Dict zs->dict = dictCreate(&zsetDictType,NULL); // 创建SkipList zs->zsl = zslCreate(); o = createobject(OBJ_ZSET,zs); o->encoding = OBJ_ENCODING_SKIPLIST; return o;}ZipList 创建条件
// zadd添加元素时 , 先根据key找到zset,不存在则创建新的zsetzobj lookupKeyWrite(c->db,key);if (checkType(c,zobj,OBJ_ZSET))goto cleanup; //判断是否存在if(Zobj==NULL){ // 判断采用 HT+SkipList/ZipList 方案 // server.zset_max_ziplist_entries配置 禁用/启用 // 或者 value大小超过了zset_max_ziplist_value if (server.zset_max_ziplist_entries == 0 || server.zset_max_ziplist_value sdslen(c->argv[scoreidx+1]->ptr)) { // 采用 HT+SkipList zobj = createzsetobject(); }else{ // 采用 ZipList zobj = createzsetziplistobject(); } dbAdd(c->db,key,zobj);}//..zsetAdd(zobj,score,ele,flags,&retflags,&newscore);结构图 :
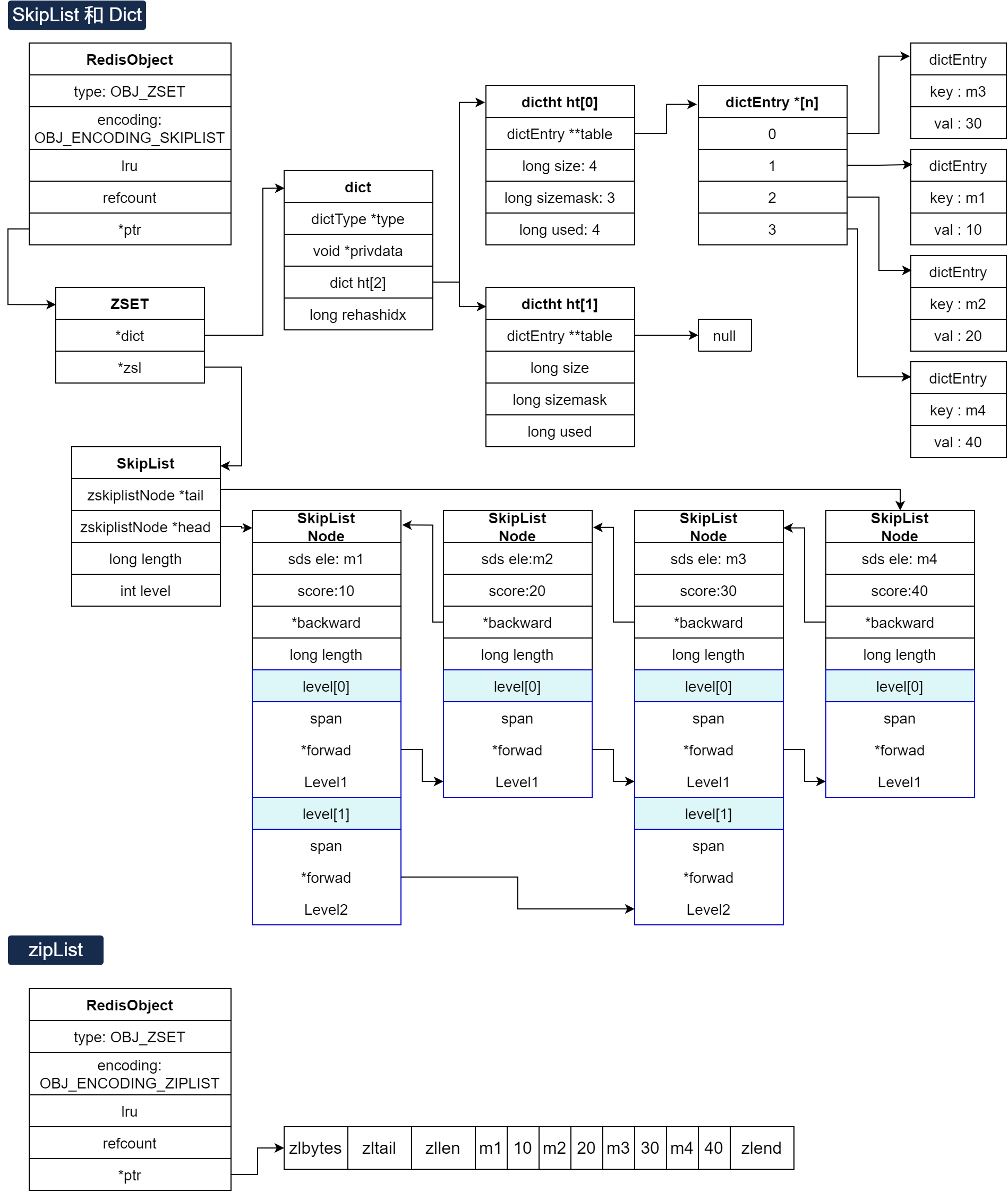
# 2.12 Hash
特点 :
- 键值对存储
- 按 key 获取值
- key 唯一
Hash 编码选型 :
- ZipList 编码 , 连续内存的 键值 Entry 成对出现 , 节省内存 , 也是默认采用编码
- HT 编码(Dict) , 数据较大时 , 以下采用条件 :
- ziplist 元素总数 >= hash-max-ziplist-entries , 默认 512(可配置)
- ziplist 中任意元素大小 >= hash-max-ziplist-value , 默认 64 字节(可配置)
ZipList 编码转化 HT 编码情况
在采用 ZipList 编码的时 , 每当 插入/更改 元素 , 都会检测该元素的类型是否满足 , 如果不满足则转换为 HT 编码
ZipList 存储的结构
| zlbytes | zltail | zllen | ”name" | "Sans" | "age” | 21 | … | zlend |
|---|
# 3. 网络模型
# 3.1 用户空间和内核空间
在 Linux 中 , 用户空间和内核空间是通过分页机制进行隔离的 , 为了提高系统稳定性和安全性 , 并将两者进行隔离 . 同时 , 内核空间也可以通过硬件保护机制来保护自身不被用户进程非法访问
为了防止用户应用导致冲突影响内核 , 用户应用于内核隔离为两部分 :
- 用户空间 : 用户进程所处的虚拟内存空间 . 不能访问内核空间 , 必须通过内核提供接口实现
- 内核空间 : 操作系统内核所处的虚拟内存空间 . 调用一切系统资源
例如我们分配空间的如下 : (32 位空间 4GB)
| 内核空间 1GB | 用户空间 3GB |
|---|
# 3.2 阻塞 IO
阻塞 IO 是指 当程序进行输入输出操作时 , 如果遇到 阻塞(等待数据读取/写入完成) 时 , 它将一直等待直到操作 完成/超时 两种结果 , 这期间该程序将无法执行其他任务
通过时间线呈现阻塞 IO 过程 :
| 时间 | 用户 | 内核 |
|---|---|---|
| T1 | 调用 recvfrom , 查数据 | 暂无数据 |
| T2 | 等待 | 暂无数据 |
| T3 | 等待 | 数据就绪 |
| T4 | 等待 | 拷贝数据 |
| T5 | 完成 / 超时 | 拷贝完成 , 并响应 |
提示
不难看出用户在 T2 开始到 T4 期间在阻塞状态
# 3.2 非阻塞 IO
非阻塞 IO 是指 当程序进行输入输出操作时 , 如果遇到 阻塞(等待数据读取/写入完成) 时 , 程序不会一直等待 , 而是立即返回 , 并且在后续的操作中可以检查 IO 操作是否完成
通过时间线呈现非阻塞 IO 过程 :
| 时间 | 用户 | 内核 |
|---|---|---|
| T1 | 调用 recvfrom , 查数据 | 暂无数据 , 响应失败 |
| T2 | 调用 recvfrom , 查数据 | 暂无数据 , 响应失败 |
| T(N) | … | … |
| T(N+1) | 调用 recvfrom , 查数据 | 数据就绪 |
| T(N+2) | 完成 | 拷贝数据 响应 |
笔记
非阻塞 IO 是不断调用系统请求 , 去询问内核空间 . 在某种情况下 阻塞 IO 也不差于 非阻塞 IO
# 3.3 IO 多路复用
IO 多路复用 是一种可同时监视多个 文件描述符(FD) 的机制 , 它可以通过一次系统调用来等待多个 IO 操作完成 , 从而提高程序的效率和响应能力
点餐问题
有一些餐厅 , 顾客需要到前台跟服务员沟通点餐 , 但只有一个点餐柜台 . 在就餐高峰期 , 人数往往很多 , 当中总有些人会选择困难 , 不知道要点什么 , 导致后面的人一直在等待 . 就好比在计算机网络中 , 程序等待数据就绪一样 , 会导致 阻塞 IO
为了解决这个问题 , 该餐厅进行了一次升级 , 改为扫码点餐 . 现在 , 当用户想好要点什么 , 就通过手机点餐 , 订单发送到前台的打印机 , 通知厨师… 这个流程类似于 IO 多路复用的优化方案 , 避免了等待用户点餐思考而产生的阻塞时间
文件描述符 (FD) , 是一个从 0 开始的无符号整数 , 用来关联 Linux 中的一个文件 . 在 Linux 中 , 一切皆文件 , 例如常规文件、视频、硬件设备等 , 当然也包括网络套接字(Socket)
通过时间线呈现非阻塞 IO 过程 :
| 时间 | 用户 | 内核 |
|---|---|---|
| T1 | 调用 select , 监听多个 FD | 暂无数据 , 等待数据(监控) |
| T2 | … | 暂无数据 , 等待数据(监控) |
| T3 | … | 暂无数据 , 等待数据(监控) |
| T N | … | … |
| T(N+1) | - | 数据就绪 , 可能响应多个 socket 数据(FD) |
| T(N+2) | 调用 recvfrom , 查数据 | 拷贝数据 |
| T(N+3) | 完成 | 响应数据 |
提示
监控的数据可能会响应多个 socket , 调用 recvfrom 是循环进行调用的 , 并非一起调用
IO 多路复用 监听 FD 方式 和 通知方式形式有很多中 , 常见的有 :
监听 FD 方式的差异
- select 和 poll 只会通知用户进程有 FD 就绪 , 但不确定具体是哪个 FD , 需要用户进程逐个遍历 FD 来确认
- epoll 则会在通知用户进程 FD 就绪的同时 , 把已就绪的 FD 写入用户空间
# 3.3.1 select
select 是 Linux 中的早期 IO 多路复用技术的监听方案 , 实现 一个系统调用同时监控多个文件描述符的状态 , 以便在有数据 可读/写入 的时候立即处理 .
缺点 :
- 设计多次拷贝 , 要将这个 fd_set 从用户空间拷贝到内核空间 , select 结束后再次拷贝回来覆盖用户控件的 fd_set
- 无法得知 具体哪个 fd 就绪 , 需要遍历 fd_set 集合
- fd_set 集合 最大设定 fd 数量 1024
笔记
select 是早期设计的思路 , 学习了解 , 无需深入 . 现在学习应用 epoll
select 运作过程 :
-
用户空间操作 创建 fd_set rfds (记录 fd 监听)
… 0 0 0 0 0 0 0 0 0 -
用户空间操作 指定监听 fd = {1, 2, 5}
… 0 0 0 0 1 0 0 1 1 -
用户空间操作 执行 select(5+1, rfds, null, null, 3) (参数可参考以下源码)
-
内核空间操作 遍历接收的 fd_set ,
-
内核空间操作 如果没有就绪 , 则休眠等待 3s , 休眠后再次遍历集合 (有就绪直接响应结果)
-
内核空间操作 监听有数据变化着将 1 设为 0 , 并拷贝响应
-
用户空间操作 收到响应数据 fd_set , 遍历找到就绪的 fd , 去读其中的数据
监听执行方式
文件标识符(FD)采用的是比特位进行记录 , 每个 bit 位代表一个 fd , 1 代表要监听的 fd , 调用 select 时会监听 1 的值 , 0 代表
select 源码
源码 点击展开
// 定义类型别名fd_mask,本质是long inttypedef Long int __fd_mask;
// fd_set记录要监听的fd集合, 及其对应状态typedef struct { // fds_bits是long类型数组 , 长度: 1024/32=32 // 共1024个bit位 , 每个bit位代表一个fd, 0:未就绪/1:就绪 // __fd_mask类型是int(4bytes), 那么 数组大小为 32(数组大小)*32bit(类型)= 1024bit __fd_mask fds_bits[__FD_SETSIZE / __NFDBITS]; // ..} fd_set;
// select函数 , 用于监听fd_set , 也就是多个fd的集合int select( // 要监视的fd_set的最大fd+1(控制最大限度) int nfds, // 分别监听fd的 读/写/异常 事件 // 要监听读事件的fd集合 fd_set *readfds, // 要监听写事件的fd集合 fd_set *writefds, // 要监听异常事件的fd集合 fd_set *exceptfds, //超时时间 , nuL1-用不超时; 0:不阻塞等待/大于0:固定等待时间 struct timeval *timeout);# 3.3.2 poll
poll 模式对 select 做了简单改进 , 性能仍然不明显
相比 select:
- pollfd 采用链表 , 无上限 pd 数量
- 监听 fd 越多 , 每次上线消耗时间越久 , 性能下降
poll 运作过程 :
- 创建 pollfd 数组 , 向其中添加相关 fd 信息
- 调用 poll() , 将 pollfd 数组拷贝到内核空间 , 转链表(无上限)
- 内核遍历 fd , 判断是否就绪
- 数据就绪/超时后 , 拷贝 pollfd 数组到用户空间 , 返回就绪 fd 数量 n
- 用户进程判断 n 是否大于 0
- 大于 0 则 , 遍历 pollfd 数组 , 找到就绪的 fd
poll 源码
源码 点击展示
// pollfd中的事件类型#define POLLIN // 可读事件#define POLLOUT // 可写事件#define POLLERR // 错误事件#define POLLNVAL // fd未打开
// pollfd结构struct pollfd { // 要监听的fd int fd; // 要监听的事件类型 : 读、写、异常 short int events; // 实际发生的事件类型 short int revents;};
// poll函数int poll( // pollfd数组 , 可以自定义大小 struct pollfd *fds, //数组元素个数 nfds_t nfds, //超时时间 int timeout}# 3.3.3 epoll
epoll 模式对 select 和 poll 进行了改进
痛点解决 :
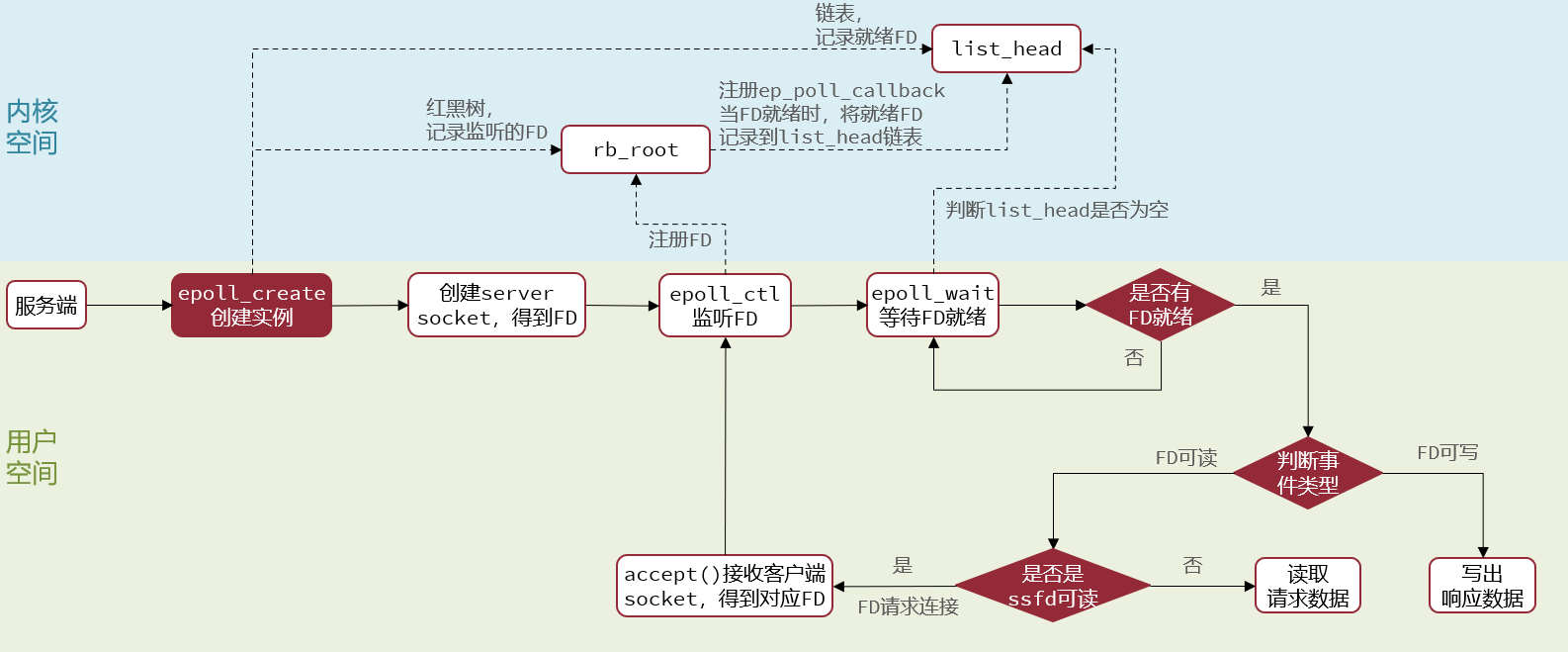
- epoll 实例中采用红黑树回调形式监听 FD , 且无上限 , 增删改查性能高
- 每个 FD 只需要执行一次 epoll_ctl 添加到红黑树 , 以后每次 epoll_wait 无需传递任何参数 , 无需重复拷贝 FD 到内核空间
- 采用回调机制监听 FD 状态 , 状态就绪添加至 rdlist 并返回 , 无需返回遍历所有 FD
poll 运作过程 :
- 创建 epoll_create() 实例
- 调用 epoll_ctl() , 添加监听 FD , 关联回调函数(用于回调加入 rdlist 就绪链表)
- 调用 epoll_wait , 等待检查 rdlist 链表返回 , 按超时时间等待
epoll 源码
源码 点击展开
struct eventpoll{ // ... // 一颗红黑树 , 记录要监听的FD struct rb_root rbr; // 一个链表 , 记录就绪的FD struct list_head rdlist; // ...};// 1.在内核创建eventpoll结构体 , 返回对应的句柄epfdint epoll_create(int size);
// 2.将一个FD添加到epoll的红黑树中, 并设置ep_poLL_callback// callback(回调函数)触发时, 就把对应的FD加入到rdlist这个就绪列表中int epoll_ctl( // epoll实例的句柄 int epfd, // 要执行的操作, 包括: ADD、MOD、DEL int op, // 要监听的FD int fd, // 要监听的事件类型: 读、写、异常等 struct epoll_event *event);// 3.检查rdlist列表是否为空, 不为空则返回就绪的FD的数量int epoll_wait( //eventpoll实例的句柄 int epfd, // 空event数组, 用于接收就绪的FD struct epoll_event *events, // events数组的最大长度 int maxevents, //超时时间. -1不超时;0不等待;>0等待时长 int timeout);# 3.3.4 事件通知机制
当 FD 有数据可读时 , 调用 epoll_wait()得到通知 , 但是事件通知的模式有两种 :
- LevelTriggered(LT) : 只要某个 FD 中有数据可读 , 每次调用 epoll_wait 都会得到通知
- EdgeTriggered(ET) : 只有在某个 FD 有状态变化时 , 调用 epoll_wait 才会被通知
注意
当使用 ET 模式时 , 必须确保在文件描述符状态发生变化时及时处理事件 , 否则可能会出现事件丢失的情况
例子 : (采用 LT)
- 假设一个客户端 scoket 对应的 FD 已经注册到了 epoll 实例中
- 客户端 socket 发送 2KB 数据
- 客户端调用 epoll_wait() 等待 FD 通知(发送的数据已就绪立即返回) . 会立即返回之前已经就绪但是没有被处理的 FD , 直到所有 FD 读取完
- 服务端从 FD 读取 1kb 数据
- 返回步骤 3(才次调用 epoll_wait())
LT 和 ET 对 FD 文件处理方式 :
- 客户端 发送数据后
- 内核 红黑树当中有 FD 数据就绪 , 并且添加到 rdlist 链表
- 客户端 调用 epoll_wait() 后 , 内核会将 断开 rdlist 链表(指针移除) , 并拷贝就绪数据给用户空间
- 内核 根据不同通知机制来进行抉择 如下 :
- LT : 重新链接 rdlist 链表 指针指向
- ET : 断开 rdlist 链表元素之间的 指针指向 , 并删除 (才次调用 epoll_wait()结果为 null)
LT 存在的问题 :
- 阻塞 , FD 就卡在差一点没读完(读不了) , 从而导致阻塞
- 无效 FD , 重复调用 epoll_wait() , 响应可能已经读取的 FD , 损耗内存
- 当有 N 个进程共同监听有 FD 文件 , 并都调用有 epoll_wait() , 所有进程都会唤醒
LT 模式并非没有优点 , 它能够确保事件一定会被处理 , 且处理方式更加灵活
# 3.3.5 web 服务流程
基于 epoll 模式 web 服务的基本流程 :
# 3.4 信号驱动 IO
信号驱动 IO 是一种用于处理异步 IO(非阻塞 IO)的机制
在信号驱动 IO 机制中 , 进程在发起 IO 操作时 , 可以指定一个信号(SIGIO) , 以便当 IO 操作完成时 , 内核会向进程发送该信号 . 进程可以注册一个信号处理函数来处理该信号 , 从而获得 IO 操作的结果
大致流程
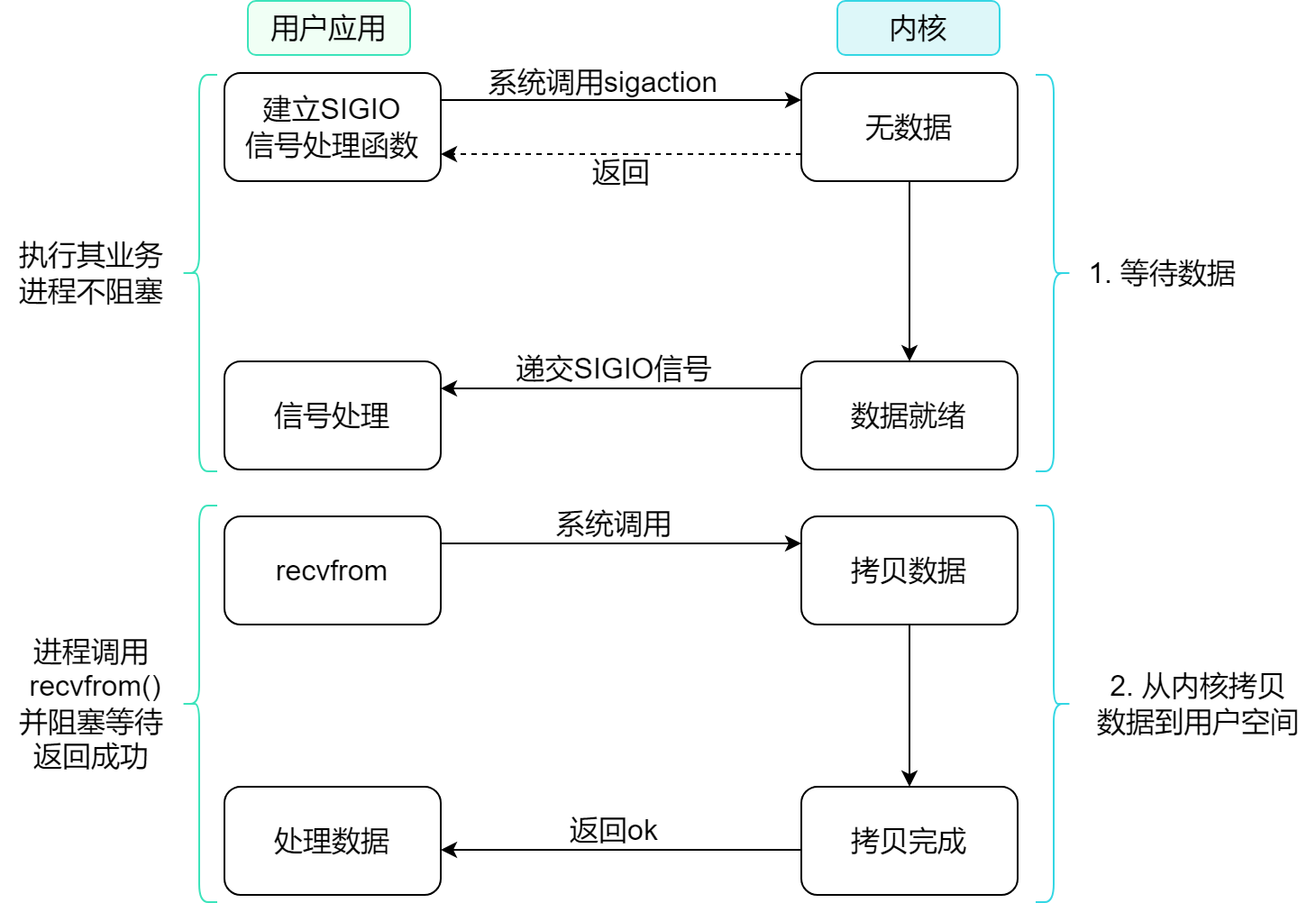
不常用 信号驱动 IO 的原因
- 当有大量的 IO 操作时 , 信号较多时 , 可能会导致信号队列溢出问题
- 内核空间和用户空间 频繁信号交互性能比较低
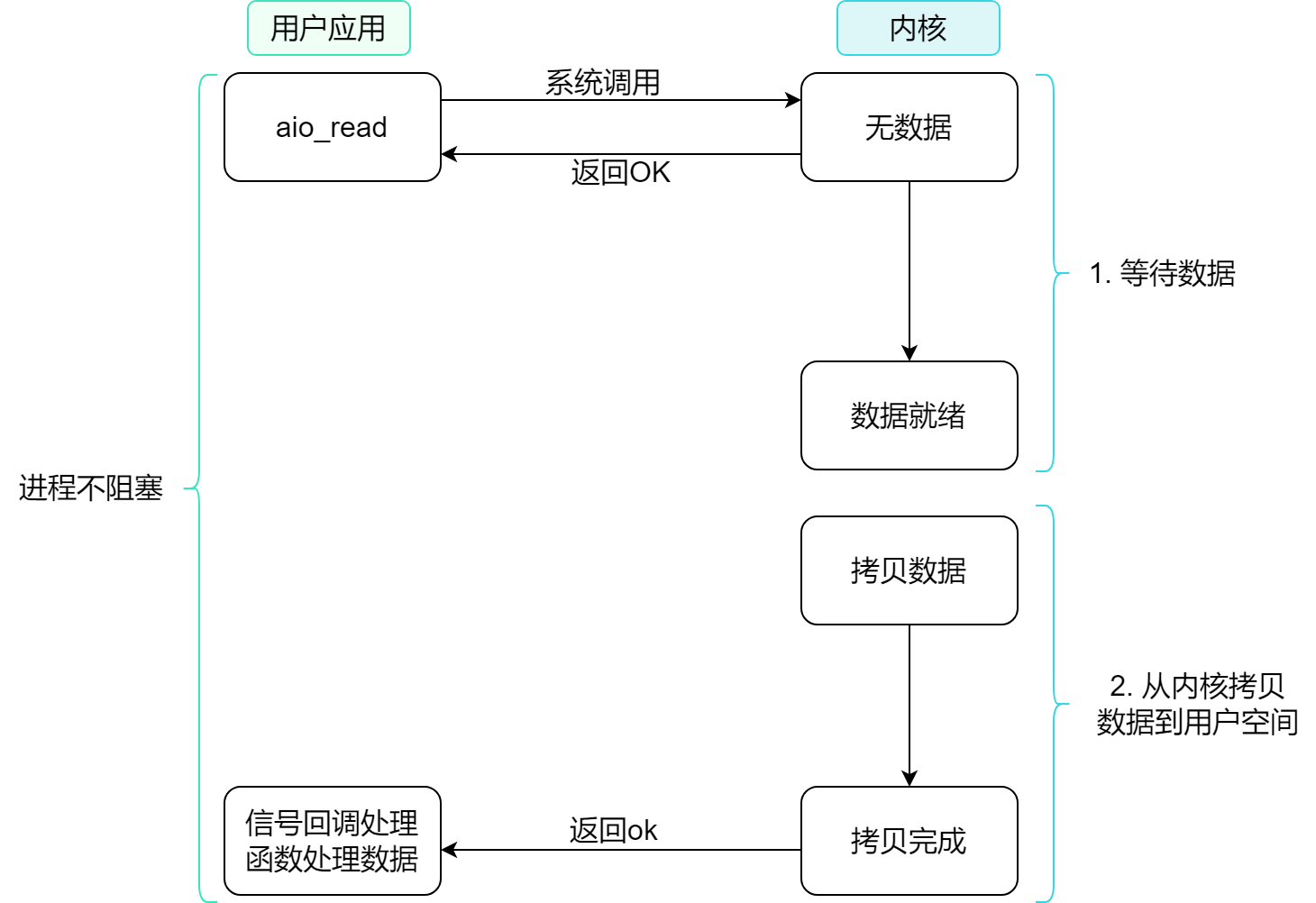
# 3.5 异步 IO
异步 IO 的整个过程都是非阻塞的 , 用户进程调用完异步 API 后就可以去做其它事情 . 当 IO 操作完成时 , 内核会调用注册的回调函数 , 让程序处理已经完成的 IO 操作 . 此外 , 程序还需要使用特定的 API 来启动和管理异步 IO 操作
大致流程
# 3.6 Redis 网络模型
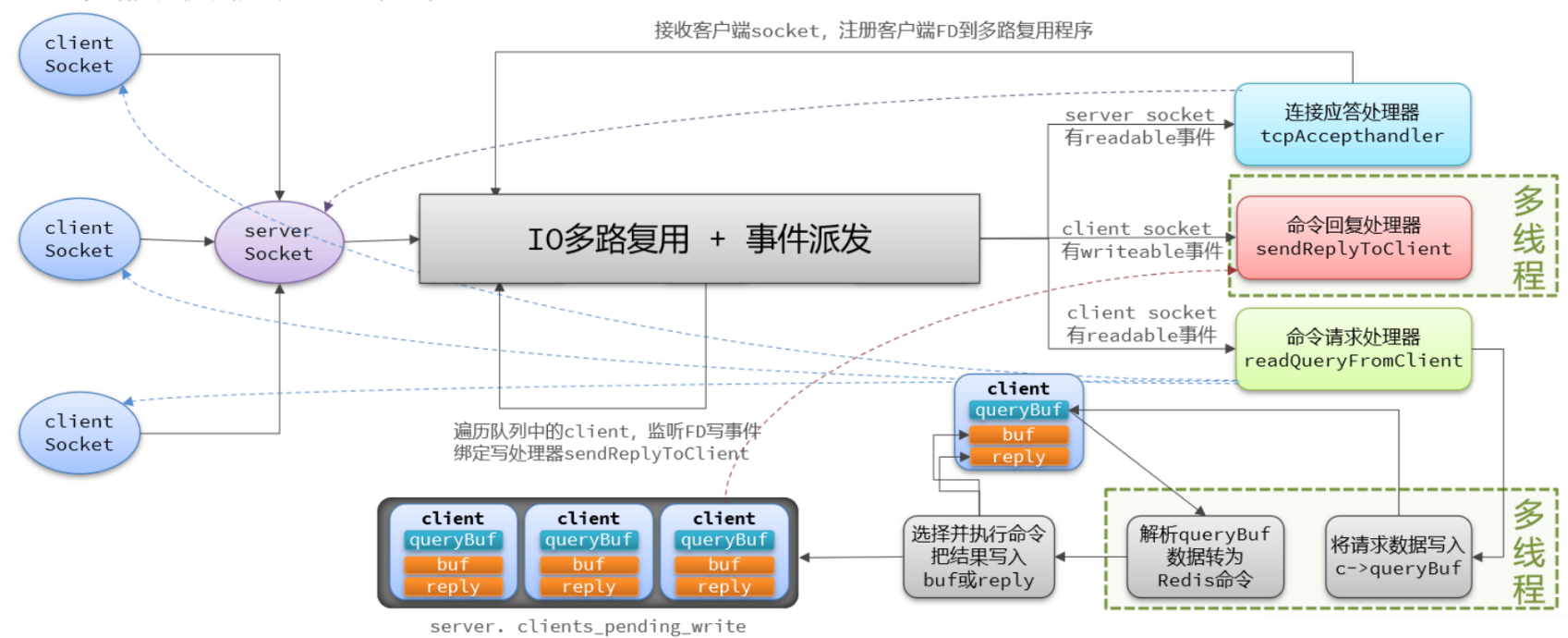
Redis 是个纯内存操作 , 它是采用单线程运作 , 网络 IO 操作都是都是在一个线程里完成
主要组件 :
- 事件循环器(核心) : 它会无限循环等待新的事件发生 , 并且根据不同的事件类型调用相应的处理函数 (处理客户端的连接请求/读写网络数据/…)
- 文件事件(事件类型) : 包括了可读事件/可写事件/异常事件等 , 这些事件都是基于套接字的网络 IO 操作(接受新连接/读取客户端发送的数据/发送响应数据/…)
大致过程 :
- 客户端连接 Redis 服务器 , 建立 TCP 连接
- Reids 将客户端连接封装成一个 client 结构体(包含有 套接字描述/输入缓冲区/输出缓冲区/… 等信息)
- 当客户端发送请求时 , Redis 会将请求数据从套接字读取到输入缓冲区中
- Redis 的事件循环器 , 根据不同的事件类型调用相应的处理函数(处理客户端连接请求/读写网络数据)
- Redis 接收到请求 , 根据对应的请求类型调用处理函数 , 处理函数所需的参数会从输入缓冲区中读取请求数据
- 处理函数的结果会写入输出缓冲区中 , 并通过套接字发送给客户端
- 客户端收到响应数据时 , 会从套接字读取到本地缓冲区中 , 然后处理…
- 当客户端断开连接时 , Redis 会清理该客户端的 client 结构体 , 并断开该客户端的相关套接字连接
流程图 :
Redis 业务处理仍然选择单线程的原因
- 线程问题 . 引入多线程必然会面临的问题 : 上下文切换/性能开销/线程安全/线程锁/…
- 响应速度 . Redis 是纯内存操作 , 速度非常快 , 响应速度的瓶颈还卡在网络延迟问题
# 4. 通信协议
# 4.1 RESP 协议
RESP 协议是一种文本协议 , 用于客户端与 Redis 服务器之间的通信
提示
本次学习 RESP2 协议
RESP 协议数据类型 :
| 数据类型 | 结构 | 示例 |
|---|---|---|
| 单行字符串 | + + 字符串内容 + \r\n | ”ok” => “+ok\r\n” |
| 错误 | - + 字符串内容 + \r\n | ”-Error message\r\n” |
| 数值 | : + 整型 + \r\n | ”:10\r\n” |
| 多行字符串 | $n + 多行内容 + \r\n\r\n(含有两个情况) | 以下特别说明 |
| 数组 | *n + 元素 1+元素 2+.. | 以下特别说明 |
多行字符串 : $后面的 n 代表字符串的长度 , 最大支持 512MB . 以下使用方式 :
$25\r\nThis is a multi-line string\r\nthat spans multiple lines.\r\n\r\n结构说明
每行都已 \r\n 结尾进行换行 , 第一行以 $25 开始 , 表示字符串的总长度为 25 个字节 . 第二行和第三行分别包含 “This is a multi-line string” 和 “that spans multiple lines.” 两个子字符串 , 最后一行只包含两个 \r\n , 表示字符串的结束
数组 : $后面的 n 代表数组 n 个元素 . 以下使用方式 :
*3\r\n$3\r\nset\r\n$4\r\nname\r\n$4\r\nSans\r\n结构说明
每一个头标识作为一个元素的开始 , 一共有 3 个 ` , 他们分别是 [‘set’,‘name’,‘Sans’]
# 4.2 Java 模拟 Redis 客户端
以 Main 通信测试 :
代码示例 点击展开
public class Main {
public static Socket socket = null; public static PrintWriter writer; public static BufferedReader reader;
public static void main(String[] args) { String host = "192.xxx.xx"; String password = "123123"; int port = 6379;
try { // 1. 建立连接 socket = new Socket(host, port); // 2. 获取 输入/输出 流 (字符流) writer = new PrintWriter( new OutputStreamWriter(socket.getOutputStream(), StandardCharsets.UTF_8)); reader = new BufferedReader( new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8)); // 3. 认证 sendRequest("auth", password); Object obj = handleResponse(); System.out.println("登录 => " + obj); // 4. 发送 命令请求 // set测试 //sendRequest("set", "name2", "张三"); // get测试 //sendRequest("get","name"); sendRequest("mget", "name", "name2"); // 异常测试 (不存在) //sendRequest("get","xa"); // 5. 解析响应 obj = handleResponse(); System.out.println("res => " + obj); } catch (Exception e) { throw new RuntimeException(e); } finally { try { // 6. 释放连接 if (reader != null) reader.close(); if (writer != null) writer.close(); if (socket != null) socket.close(); } catch (Exception e) { e.printStackTrace(); }
} }
private static Object handleResponse() throws IOException { // 读取首字节 , 判断类型 int prefix = reader.read(); switch (prefix) { case '+': return reader.readLine(); case '-': throw new RuntimeException(reader.readLine()); case ':': return Long.parseLong(reader.readLine()); case ': // 新读取长度 , 后读数据 long len = Long.parseLong(reader.readLine()); if (len == -1) return null; if (len == 0) return ""; return reader.readLine(); case '*': return readBulkString(); default: throw new RuntimeException("未知格式"); } }
private static Object readBulkString() throws IOException { // 循环读取 long len = Long.parseLong(reader.readLine()); if (len <= 0) return null; List<Object> list = new ArrayList<>(); for (int i = 0; i < len; i++) { list.add(handleResponse()); } return list; }
private static void sendRequest(String... ages) { writer.println("*" + ages.length); for (String age : ages) { // 字节大小(并非字符个数) writer.println("$" + age.getBytes(StandardCharsets.UTF_8).length); writer.println(age); } writer.flush(); }
}提示
- 每次发送请求后都要对应读取响应
- 写入缓冲区后的命令 , 写完后一定要刷新
# 5. Redis 内存策略
# 5.1 过期策略
Redis 中的过期机制必不可少 , 它之所以强 , 是因为它是基于内存实现 , 且内存的容量是有限的
Redis 是通过一个新的结构体 redisDb 存过期时间以及其他属性 :
redisDb 结构体源码 点击展开
typedef struct redisDb { // 存储 key-value本身 dict *dict; // 存过期时间 key-ttl dict *expires; dict *blocking_keys; dict *ready_keys; dict *watched_keys; int id; /* Database ID , 0~15 */ long long avg_ttl; /* 记录平均TTL时长 */ unsigned long expires_cursor;/* expire检查时在dict中抽样的索引位置. */ list *defrag_later; /* 等待碎片整理的key列表. */} redisDb;key 过期策略 :
- 惰性过期
- 定期过期
惰性过期
客户端请求访问过期 key 时 , 会对其 key 检查 ttl , 如果 key 过期返回 nil , 并删除
惰性过期源码 点击展开
// 查找一个key执行写操作robj *lookupKeyWriteWithFlags(redisDb *db, robj *key, int flags) { // 检查key是否过期 expireIfNeeded(db,key); return lookupKey(db,key,flags);}// 查找一个key执行读操作robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) { robj *val; // 检查key是否过期 if (expireIfNeeded(db,key) == 1) { // ... } return NULL;}
int expireIfNeeded(redisDb *db, robj *key) { // 判断是否过期 , 如果未过期直接结束并返回0 if (!keyIsExpired(db,key)) return 0; // ... // 删除过期key deleteExpiredKeyAndPropagate(db,key); return 1;}遗留问题
如果长期没有得到访问 , 该数据内存则会长期卡在内存中 , 从而引起内存浪费!
定期过期
定期扫描过期 key 并对其过期 key 删除 , 周期执行种类有两种 :
- SLOW 模式
- FAST 模式
SLOW 模式
定时任务执行 serverCron() , 按照 server.hz 频率执行过期 key 清理 . 该模式有以下规则 :
- 执行频率 , 运作周期受 server.hz 影响(默认 10) , 周期 100ms(10 次/秒)
- 清除时长 , 在每个运作的周期中 , 清除 key 所需的时间不能超过 周期单位的 25%(默认 25ms)
- 逐个遍历 db , 遍历 db 中的 bucket 哈希表数组的每个角标(进度) , 抽取 20 个 key 进行判断过期
- 如果清除时长没有达到上限(默认 25ms) , 且 key 过期比例大于 10% , 会再次进行一次抽样 , 否则结束
SLOW 模式源码
// 初始化void initServer(void){ // ... // 创建定时器 , 关联回调函数serverCron , 处理周期取决于server.hz , 默认10 aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL);}
// 定期执行int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) { // 更新lruclock到当前时间 , 为后期的LRU和LFU做准备 unsigned int lruclock = getLRUClock(); atomicSet(server.lruclock,lruclock); // 执行database的数据清理 , 例如过期key处理 databasesCron(); // 返回等待加载下一周期的时间 100(1000/10) return 1000/server.hz;}
// 清除任务void databasesCron(void) { // 尝试清理部分过期key , 清理模式默认为SLOW activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);}FAST 模式
每个事件循环前会调用 beforeSleep()函数 , 清理过期 key . 该模式有以下规则 :
- 执行频率 , 运作周期受 beforeSleep()调用频率 , 频率不固定 , 但两次间隔不低于 2ms
- 清除时长 , 清除耗时不超过 1ms
- 逐个遍历 db , 遍历 db 中的 bucket 哈希表数组的每个角标(进度) , 抽取 20 个 key 进行判断过期
- 如果清除时长没有达到上限(默认 1ms) , 且 key 过期比例大于 10% , 会再次进行一次抽样 , 否则结束
FAST 模式源码 点击展开
// 事件触发void aeMain(aeEventLoop *eventLoop){ eventLoop->stop = 0; while(!eventLoop->stop){ // beforeSleep() --> FAST模式清理 // n = aeApiPoll() // 如果 n>0 , FD就绪 , 处理IO事件 // 如果到了执行时间 , 则调用 serverCron() --> SLOW模式清理 }}
// 清除任务void beforeSleep(struct aeEventLoop *eventLoop){ // ... // 尝试清理部分过期key , 清理模式默认为FAST activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);}SLOW 与 FAST 区别
| SLOW 模式 | FAST 模式 | |
|---|---|---|
| 执行速度 | <=10ms | <=1ms |
| 清理量 | 大量 | 少量 |
| 周期频率 | 低频(100ms) | 高频 |
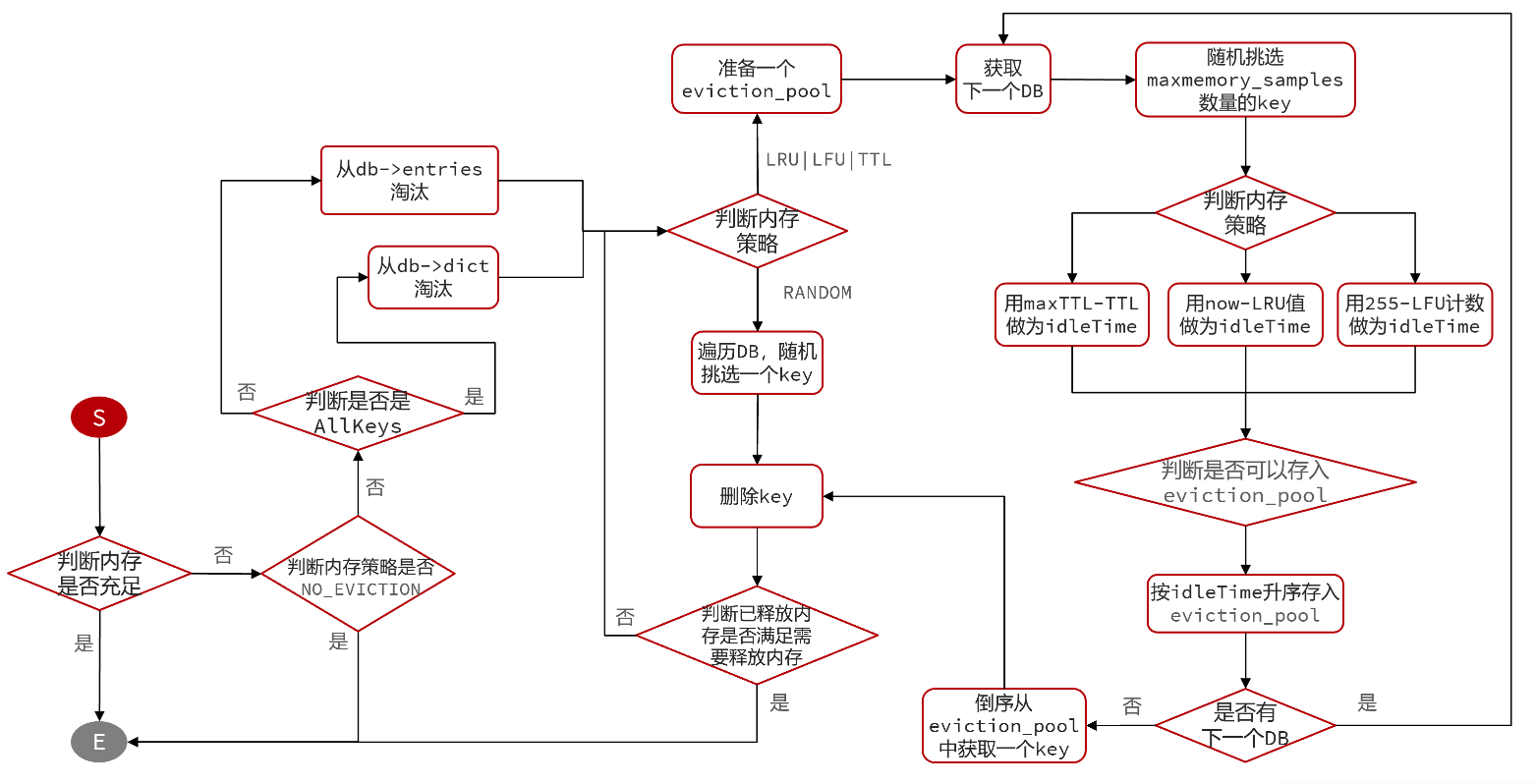
# 5.2 淘汰策略
Redis 中的内存淘汰机制是指 当 Redis 占用的内存超过了物理内存限制 或者 超过 server.maxmemory 配置的上限 时 , 主动的去 删除部分 key , 以达释放内存应用
淘汰策略 :
以下淘汰策略可以在 Redis 配置中的 maxmemory-policy选项配置
- noeviction : 禁止淘汰 (默认) , 当内存到达上限时 , 拒绝所有写入操作
- volatile-ttl : 淘汰最小 ttl , 仅对设置了 ttl , 且 ttl 最小的最优先淘汰
- allkeys-random : 随机 key 淘汰 , 对所有 key 进行随机淘汰
- volatile-random : 随机 ttl 淘汰 , 对所有设置了 ttl 进行随机淘汰
- allkeys-lru : LRU 算法 key 淘汰 , 使用 LRU 算法对 key 选择淘汰
- volatile-lru : LRU 算法 ttl 淘汰 , 使用 LRU 算法对 ttl 选择淘汰
- allkeys-lfu : LFU 算法 key 淘汰 , 使用 LFU 算法对 key 选择淘汰
- volatile-lfu : LFU 算法 ttl 淘汰 , 使用 LFU 算法对 ttl 选择淘汰
LRU 与 LFU 说明
LRU : 最近最少使用 . 根据 当前时间减去最后一次访问时间 , 值越大越优先淘汰
LFU : 最不经常使用 . 根据 统计的访问次数 , 值越小越优先淘汰
LRU 与 LFU 判断的属性 存储在 RedisObject 结构体中 , 他们存储分别是的形式 :
- LRU : 以秒为单位记录最近一次访问时间 , 长度 24bit
- LFU : 高位 16 记录最近访问时间(分钟单位) ; 低位 8 记录逻辑访问次数
LFU 中的逻辑访问次数并非是统计 key 访问的次数 , 而是通过运算的 :
- 生成 0 - 1 之间的随机数 R
- 计算 (旧次数 * lfu_log_factor + 1) , 记录为 P (lfu_log_factor 默认 10)
- 如果 R < P , 则计数器 + 1 , 且最大不超过 255
- 访问次数会随时间衰减 , 距离上一次访问时间每隔 lfu_decay_time 分钟 , 计数器 - 1
- 上次访问时间间隔默认 1min
淘汰策略的流程图 :
原理篇啃了一周 , 说实话挺不容易的 , 太久没接触 c 语言了 . 上述笔记如有理解不到位 , 请在下方评论指正!
